SCANLINE IS A LIE
That’s right, the whole idea of scanline rasterization being quick and simple because we just connect two points across scanline turns out to be one big deception. I will allow myself to quote the author from this article which explains it best:
If you’ve written any software rendering code in the past, chances are good that you used a scanline rasterization approach instead: you scan the triangle from top to bottom and determine, for each scan line, where the triangle starts and ends along the x axis. While the high-level overview is easy enough, the details get fairly subtle, as for example the first two articles from Chris Hecker’s 1995-96 series on perspective texture mapping explain (links to the whole series here).
More importantly though, this kind of algorithm is forced to work line by line. This has a number of annoying implications for both modern software and hardware implementations: the algorithm is asymmetrical in x and y, which means that a very skinny triangle that’s mostly horizontal has a very different performance profile from one that’s mostly vertical. The outer scanline loop is serial, which is a serious problem for hardware implementations. The inner loop isn’t very SIMD-friendly – you want to be processing aligned groups of several pixels (usually at least 4) at once, which means you need special cases for the start of a scan line (to get up to alignment), the end of a scan line (to finish the last partial group of pixels), and short lines (scan line is over before we ever get to an aligned position). Which makes the whole thing even more orientation-dependent. If you’re trying to do mip mapping at the same time, you typically work on “quads”, groups of 2×2 pixels (explanation for why is here). Now you need to trace out two scan lines at the same time, which boils down to keeping track of the current scan conversion state for both even and odd edges separately. With two lines instead of one, the processing for the starts and end of a scan line gets even worse than it already is. And let’s not even talk about supporting pixel sample positions that aren’t strictly on a grid, as for example used in multisample antialiasing. It all goes downhill fast.
I’d say last sentence is a testament to the whole previous chapter.
So instead of scanline rasterization we will going to use much simpler approach, which I named P.I.T. Rasterizer after “Point Inside Triangle” test that is used by it. Maybe there’s an official name for this method, but I don’t know it.
Also worth mentioning that in the above article author states that this approach to rasterization has been in use since late 80s. And quick Google search (link to PDF) shows that it is an industry standard today. So your graphics card is doing this to rasterize your stuff, although on a hardware level and more sophisticated than what we’re doing here, of course. It basically splits your framebuffer into tiles and deals with them on a per core basis to maximize parallelization (check out this Wikipedia article).
One could say it’s a blast from the NES era past, so to speak, who would’ve thought! But we have a saying here that says everything new is a well forgotten old.
P.I.T. rasterizer
This method is very simple: given 3 points of a triangle we determine bounding box that surrounds it, and then iterate across it pixelwise, checking whether pixel falls inside the triangle or not.
To determine whether pixel falls inside the triangle or not we’ll use already familiar tool to us - 2D cross product that was introduced in previous chapter. In general cross product (along with dot product) is actually used quite often in computer graphics for different purposes. This is no exception: not only we can use it to determine winding order, but here we can also use it to determine whether a point lies inside the triangle or not. To do this we need to check the sign of a cross product of every triangle edge with a vector that goes from triangle vertex to the point in question.
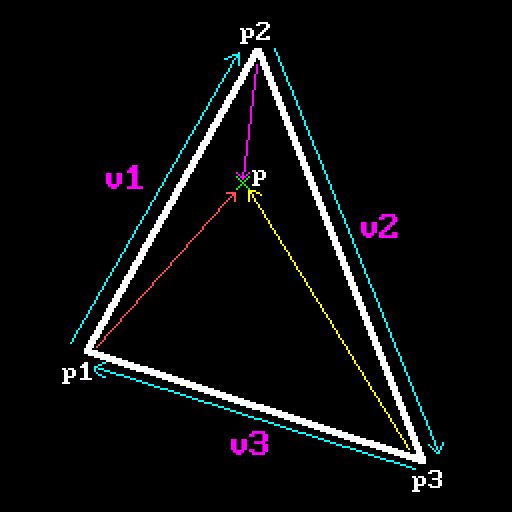
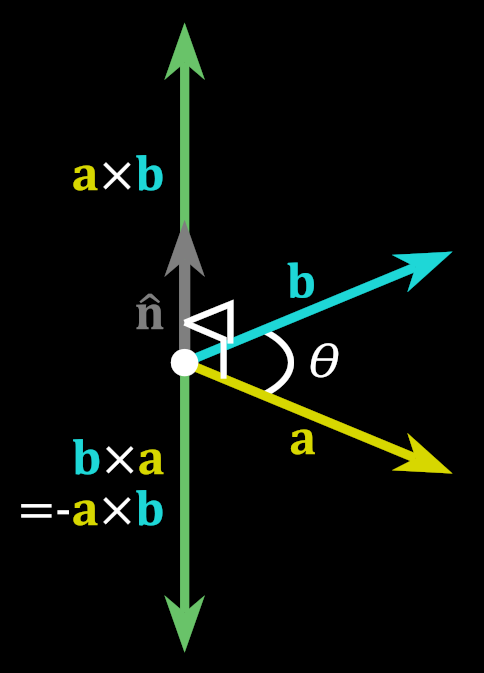
From this example you can see that if point lies inside the triangle, all cross products are performed “clockwise”: edge multiplied by the vector to the point goes in sort of clockwise direction, so they all will have the same sign. Should a point lie outside the triangle, at least one of the products will go “different way” and will have opposite sign. Here’s that picture again about order of operations for cross product:
Also let’s again recall winding order real quick:
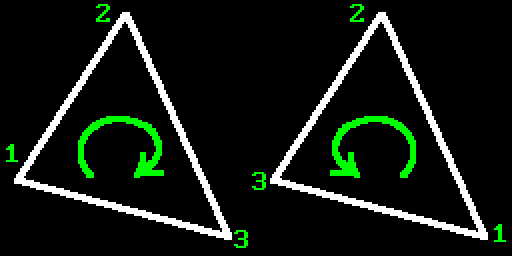
Since user can specify triangle vertices in any order, we can’t pre-agree on certain sign of the cross product to check against. But since all that we need to do is check whether all products yield the same sign or not, this will work anyway.
So our main piece of code will look like this:
int xMin = std::min( std::min(p1.x, p2.x), p3.x);
int yMin = std::min( std::min(p1.y, p2.y), p3.y);
int xMax = std::max( std::max(p1.x, p2.x), p3.x);
int yMax = std::max( std::max(p1.y, p2.y), p3.y);
for (int y = yMin; y <= yMax; y++)
{
for (int x = xMin; x <= xMax; x++)
{
SDL_Point p = { x, y };
//
// It seems that if we don't use a function call (CrossProduct2D)
// and just perform calculations directly, this way it works a
// little bit faster.
//
int w0 = (p2.x - p1.x) * (p.y - p1.y) - (p2.y - p1.y) * (p.x - p1.x);
int w1 = (p3.x - p2.x) * (p.y - p2.y) - (p3.y - p2.y) * (p.x - p2.x);
int w2 = (p1.x - p3.x) * (p.y - p3.y) - (p1.y - p3.y) * (p.x - p3.x);
bool inside = (w0 <= 0 and w1 <= 0 and w2 <= 0)
or (w0 >= 0 and w1 >= 0 and w2 >= 0);
if (inside)
{
SDL_RenderDrawPoint(_renderer, p.x, p.y);
}
}
}
OK, with this we can draw triangles all right. But just like with the case of scanline algorithm we need to implement fill convention here as well, otherwise we won’t be able to draw things properly. Since now our rasterization approach is completely different (we go pixel by pixel across a rectangle), we somehow need to determine whether given pixel belongs to the edge or not and what kind of an edge it is. The rules are actually simple:
-
If edge is horizontal and above all others, then it’s a top edge.
-
If and edge “goes up” (for CW winding order), then it’s a left edge.
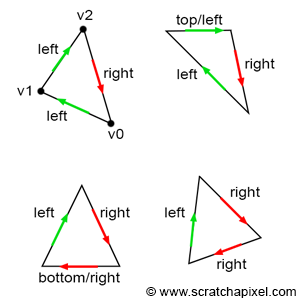
What this means is that we visit triangle vertices using our chosen winding order and find out an edge between these two points by subtracting one point from another. This will give us a vector and arrows on the picture show its direction. So for determining left edges we’re interested in vectors that go up, i.e. ones whose Y component is negative, since for edges that go up we subtract bigger Y values from smaller ones. You can see that $v_1.y$ is obviously bigger than $v_2.y$, so if we subtract $v_2-v_1$ resulting vector will have its Y component negative.
And just to note: if winding order was CCW, then left edges would be the ones that go down, so it’s the classic “the other way around” principle.
To determine top edge it’s even simpler: points that constitute such edge will end up setting zero in Y component of the resulting difference vector. And to distinguish this edge from the bottom one we also check that X component of difference vector is positive.
So to implement this rule we need to choose the winding order. For that we will salvage part of the work from previous chapter: we already have code that does sorting and winding fixing. So we will use that and thus stick to CW winding.
So here’s how our top-left edge detection function looks like:
bool PitRasterizerTLR::IsTopLeft(const SDL_Point& start, const SDL_Point& end)
{
static Vec3 edge;
edge.X = end.x - start.x;
edge.Y = end.y - start.y;
//
// top edge is the one which has the same Y (hence egde.Y == 0) and
// (edge.X > 0) to distinguish it from flat bottom. If we have consistent
// winding order we will always have (edge.X > 0) for flat top and
// (edge.X < 0) for flat bottom for CW winding order, and vice verca for CCW.
//
// If winding order were different (CCW), then everything would've been
// "swapped" around: isTopEdge would have (edge.X < 0) and
// isLeftEdge = (edge.Y > 0)
//
bool isTopEdge = (edge.Y == 0) and (edge.X > 0);
bool isLeftEdge = edge.Y < 0;
return isTopEdge || isLeftEdge;
}
Now, how can this help us to ensure proper pixel coverage?
Actually it’s dead simple. Because we’re not using subpixel precision, all we have to do is force all pixels that do not belong to top or left edge out of our triangle. Remember earlier we implemented rasterization and mentioned that sign didn’t matter as long as it was consistent? It worked because we didn’t care about vertex ordering: it worked automagically as long as the sign was the same for all cases. There can only be one type of winding order, so no matter which one it happened to be we will get either all negatives or all positives if pixel belongs to the triangle.
But now our situation is different. Now we need consistency. For CW winding order point will be considered inside the triangle only if CrossProduct2D returns positive value or zero. Zero would signify that point lies on the edge exactly. How so? Well, it happens that cross product has certain property:
Magnitude of the resulting vector is equal to the area of parallelogram formed by two multiplied vectors.
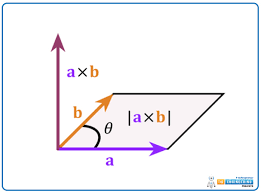
If our vectors are collinear, area will be 0, so this is our hint that point lies on the edge exactly. Since we’re working only with integers we can check strictly against 0 here, no problem.
Now, if our pixel landed on an edge that we don’t want (for example right edge), we need to force this pixel out of triangle and not draw it. So what we do is test any given pixel against three edges of a triangle and if it lands on top or left edge we do nothing - pixel belongs to the triangle. But if not we add -1 to manually shift the result of CrossProduct2D to negative domain in edge case (pun indended), and thus force ‘inside’ condition check to fail and not draw this pixel. Again, value of -1 is enough to do so because we’re not using subpixel precision and 1 is the smallest distance between two adjacent pixels.
In other words, if point lies completely inside the triangle, cross product will be positive, so adding -1 to it will either cause it to remain positive or become 0. But if cross product is 0 in the first place, then we’re on the edge and we need to check what edge it is. If it’s top or left we don’t do anything, but in other cases adding -1 to it will push such pixel out of the triangle, so to speak, and it won’t be drawn.
Here’s how part of the rasterization code looks like:
...
int bias1 = IsTopLeft(p1, p2) ? 0 : -1;
int bias2 = IsTopLeft(p2, p3) ? 0 : -1;
int bias3 = IsTopLeft(p3, p1) ? 0 : -1;
...
for (int x = xMin; x <= xMax; x++)
{
for (int y = yMin; y <= yMax; y++)
{
SDL_Point p = { x, y };
int w0 = (p2.x - p1.x) * (p.y - p1.y) - (p2.y - p1.y) * (p.x - p1.x) + bias1;
int w1 = (p3.x - p2.x) * (p.y - p2.y) - (p3.y - p2.y) * (p.x - p2.x) + bias2;
int w2 = (p1.x - p3.x) * (p.y - p3.y) - (p1.y - p3.y) * (p.x - p3.x) + bias3;
bool inside = (w0 >= 0 and w1 >= 0 and w2 >= 0);
if (inside)
{
SDL_RenderDrawPoint(_renderer, p.x, p.y);
}
}
}
Let’s test it on problematic cases from previous chapter:
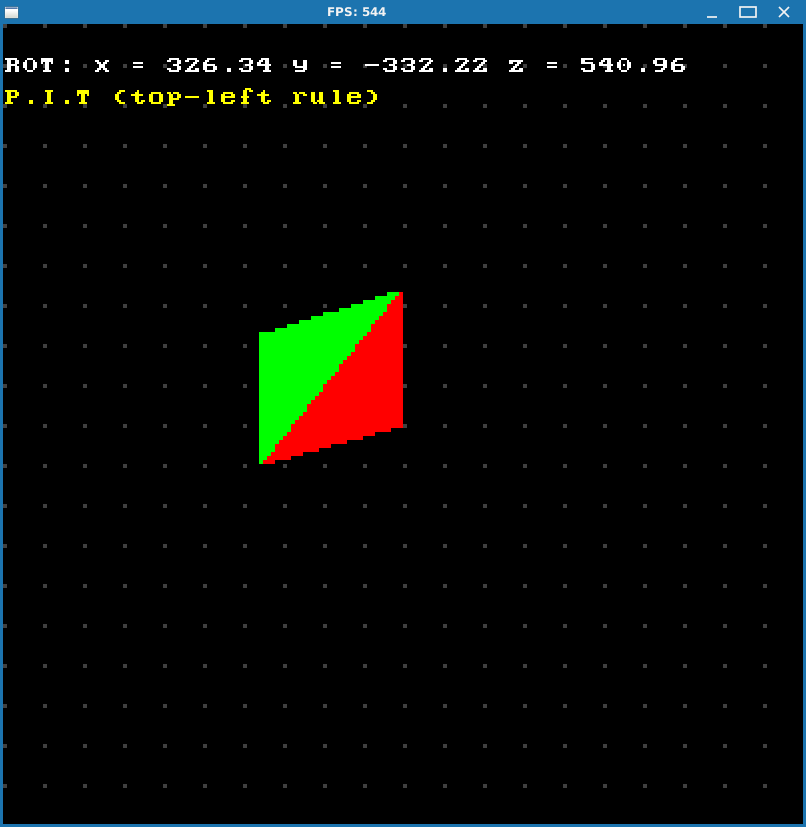
Well, everything looks great!
But before we finally move into 3D world, let’s do another quick side quest and also calculate barycentric coordinates while we’re here. It’s very easy and we’re going to use them later when we (hopefully) get to color interpolation and texture mapping.
Barycentric coordinates
Barycentric coordinates is this notion of expressing a point with relation to other three points of a triangle. It’s actually an easy concept, but I won’t go into much detail here because I’m not going to pretend to be an expert mathematician or anything, so please read about it yourself if you want some kind of scientific details. You can always start from Wikipedia of course. ;-)
But for now take a look at this live demo. I’ll just post a screenshot from it (unfortunately there’s a typo there, instead of $c_B$ it should be $x_B$):
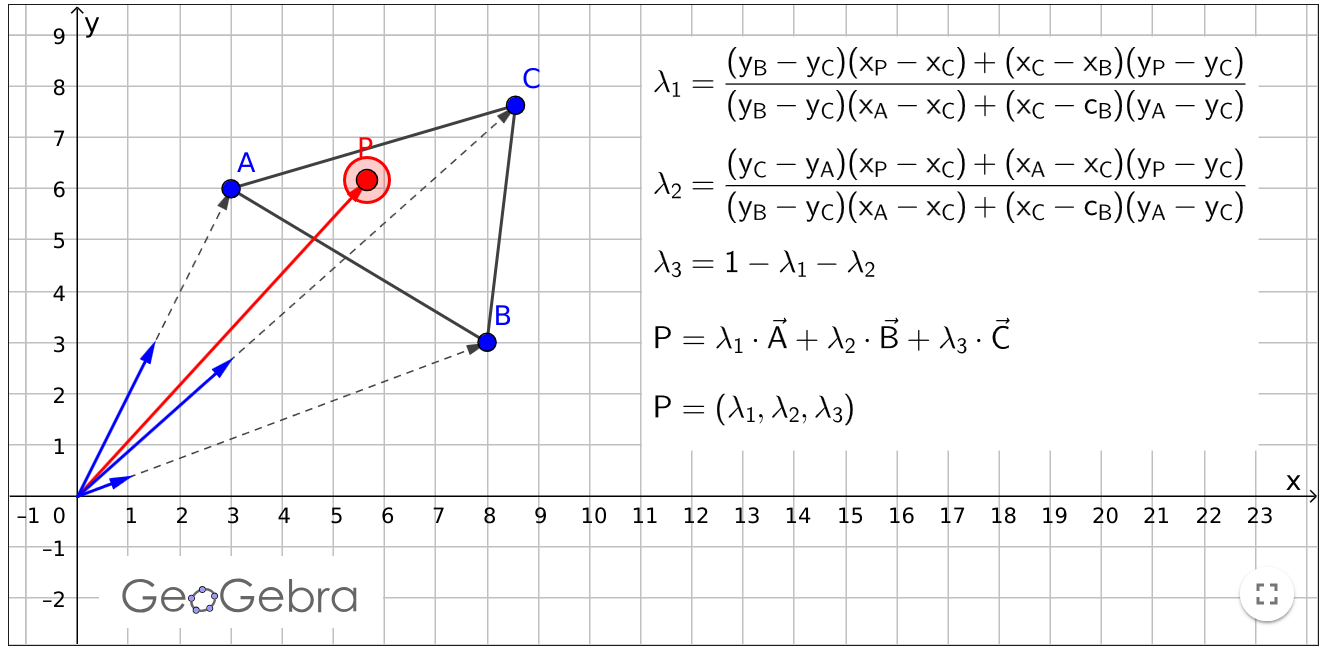
As you can see, point $P$ can be expressed as a sum of three triangle points multiplied by certain “weights” called $\lambda_1$, $\lambda_2$ and $\lambda_3$. Those expressions in braces probably look familiar by now. That’s right, it’s our CrossProduct2D again, just in different form. Let me demonstrate. Recall our cross product formula:
Now let’s assign vertices as following:
\[\begin{align*} \vec{v_1}=(B-C) \\ \vec{v_2}=(C-A) \end{align*}\]Then let’s plug that into formula for cross product:
\[(B.x-C.x)(C.y-A.y)-(B.y-C.y)(C.x-A.x)\]Or by using the screenshot’s nomenclature:
\[(x_B-x_C)(y_C-y_A)-(y_B-y_C)(x_C-x_A)\]Now it’s just a matter of applying some math wizardry:
\[\begin{align*} (x_B-x_C)(y_C-y_A)&-(y_B-y_C)(x_C-x_A) \\ (x_B-x_C)(y_C-y_A)&+(y_B-y_C)(x_A-x_C) \\ -(x_C-x_B)(y_C-y_A)&+(y_B-y_C)(x_A-x_C) \\ (x_C-x_B)(y_A-y_C)&+(y_B-y_C)(x_A-x_C) \end{align*}\]And by rearranging terms we get:
\[\boxed{(y_B-y_C)(x_A-x_C)+(x_C-x_B)(y_A-y_C)}\]Which is the same expression as the one in denominator from the example above.
As it was mentioned before, magnitude of the cross product resulting vector is an area of a parallelogram. So the expression in the denominator is actually an area of the triangle formed by its sides. And what we do next is get area of a parallelogram formed by one side of the triangle and vector going from one point of this side to the point $P$, and then divide that by the area of whole triangle (the following picture is unrelated to the screenshot from the example above):
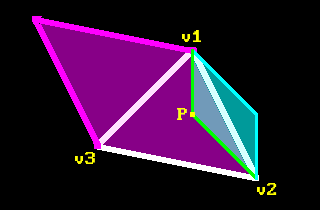
If we take cross product of $(v_2-v_1)\times(v_3-v_2)$ we can get area of the whole triangle (highlighted in magenta). Then we take cross product of $(p-v_1)\times(v_2-v_1)$ to get area highlighted in cyan. Then we divide cyan subarea against the magenta area to get one of the lambda values.
Then do that for another side. And since sum of barycentric coordinates must be equal to 1 for a point inside the triangle, we can find the third one by just subtracting $\lambda_1$ and $\lambda_2$ from 1.
We already have almost everything we need in the code except for the whole area of the triangle. We can calculate it outside the rasterization loop like so (any two edges will do, but here it’s 1-2 and 2-3):
double area = (p2.x - p1.x) * (p3.y - p2.y) - (p2.y - p1.y) * (p3.x - p2.x);
And then inside the loop we can calculate those barycentric coordinates. We are already computing those cross products with point $P$ as part of our inclusion test, so we only need to perform a division. And since we’re not interested in anything outside the triangle, we will calculate those weights only when inclusion test condition passes.
bool inside = (w0 >= 0 and w1 >= 0 and w2 >= 0);
if (inside)
{
double lambda1 = (double)cp1 / area;
double lambda2 = (double)cp2 / area;
double lambda3 = (double)cp3 / area;
// We can also do this.
//double lambda3 = 1.0 - lambda1 - lambda2;
SDL_RenderDrawPoint(_renderer, p.x, p.y);
}
Are we done yet?
Well, it’s been quite a journey to just draw a triangle! But it’s finished at last, so let’s finally proceed to the realm of 3D.